Meta tem lançado a mais recente entrada em sua série Llama de modelos de IA generativos abertos: Llama 3. Ou, mais precisamente, a empresa estreou dois modelos em sua nova família Llama 3, com o restante chegando em uma data futura não especificada.
Meta descreve os novos modelos – Llama 3 8B, que contém 8 bilhões de parâmetros, e Llama 3 70B, que contém 70 bilhões de parâmetros – como um “grande salto” em comparação com os modelos Llama da geração anterior, Llama 2 8B e Llama 2 70B, em termos de desempenho. (Os parâmetros definem essencialmente a habilidade de um modelo de IA em um problema, como analisar e gerar texto; modelos com contagem de parâmetros mais altos são, em geral, mais capazes do que modelos com contagem de parâmetros mais baixos.) Na verdade, Meta diz que, por suas respectivas contagens de parâmetros, Llama 3 8B e Llama 3 70B — treinados em dois clusters personalizados de 24.000 GPUs – são estão entre os modelos de IA generativa de melhor desempenho disponíveis atualmente.
Essa é uma afirmação e tanto. Então, como o Meta está apoiando isso? Bem, a empresa aponta para as pontuações dos modelos Llama 3 em benchmarks populares de IA como MMLU (que tenta medir o conhecimento), ARC (que tenta medir a aquisição de habilidades) e DROP (que testa o raciocínio de um modelo em pedaços de texto). Como já escrevemos antes, a utilidade — e validade — desses benchmarks está em debate. Mas, para o bem ou para o mal, eles continuam sendo uma das poucas formas padronizadas pelas quais jogadores de IA como Meta avaliam seus modelos.
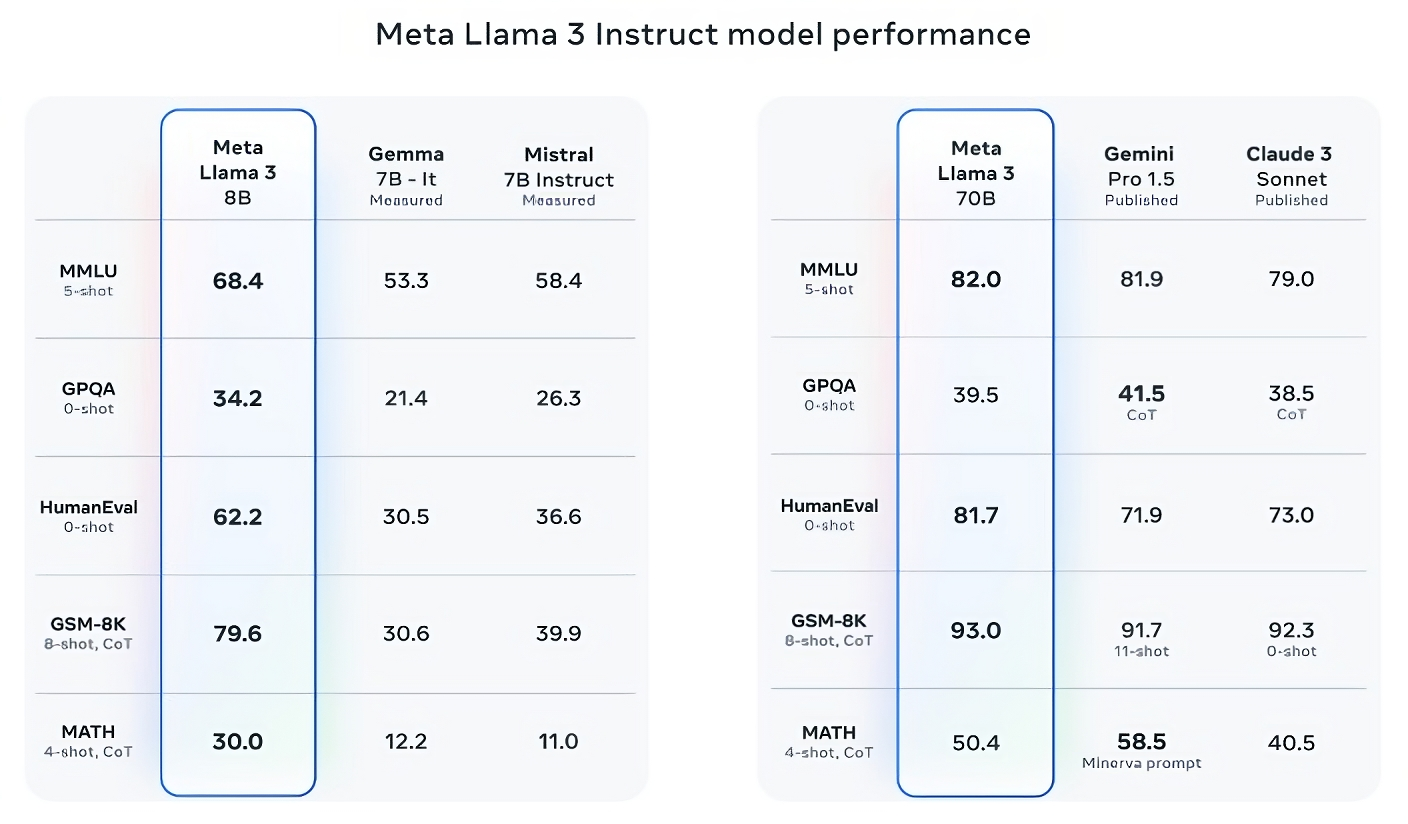
O Llama 3 8B supera outros modelos abertos, como o Mistral 7B da Mistral e o Gemma 7B do Google, ambos contendo 7 bilhões de parâmetros, em pelo menos nove benchmarks: MMLU, ARC, DROP, GPQA (um conjunto de parâmetros de biologia, física e química- questões relacionadas), HumanEval (um teste de geração de código), GSM-8K (problemas matemáticos), MATH (outro benchmark matemático), AGIEval (um conjunto de testes de resolução de problemas) e BIG-Bench Hard (uma avaliação de raciocínio de senso comum).
Agora, Mistral 7B e Gemma 7B não estão exatamente no limite (Mistral 7B foi lançado em setembro passado), e em alguns dos benchmarks que Meta cita, Llama 3 8B pontua apenas alguns pontos percentuais a mais que qualquer um. Mas Meta também afirma que o modelo Llama 3 com maior número de parâmetros, Llama 3 70B, é competitivo com os principais modelos de IA generativa, incluindo Gemini 1.5 Pro, o mais recente da série Gemini do Google.
Créditos da imagem: meta
Llama 3 70B vence Gemini 1.5 Pro em MMLU, HumanEval e GSM-8K, e – embora não rivalize com o modelo de maior desempenho da Anthropic, Claude 3 Opus – Llama 3 70B tem pontuação melhor do que o segundo modelo mais fraco da série Claude 3, Claude 3 Sonnet, em cinco benchmarks (MMLU, GPQA, HumanEval, GSM-8K e MATH).
Créditos da imagem: meta
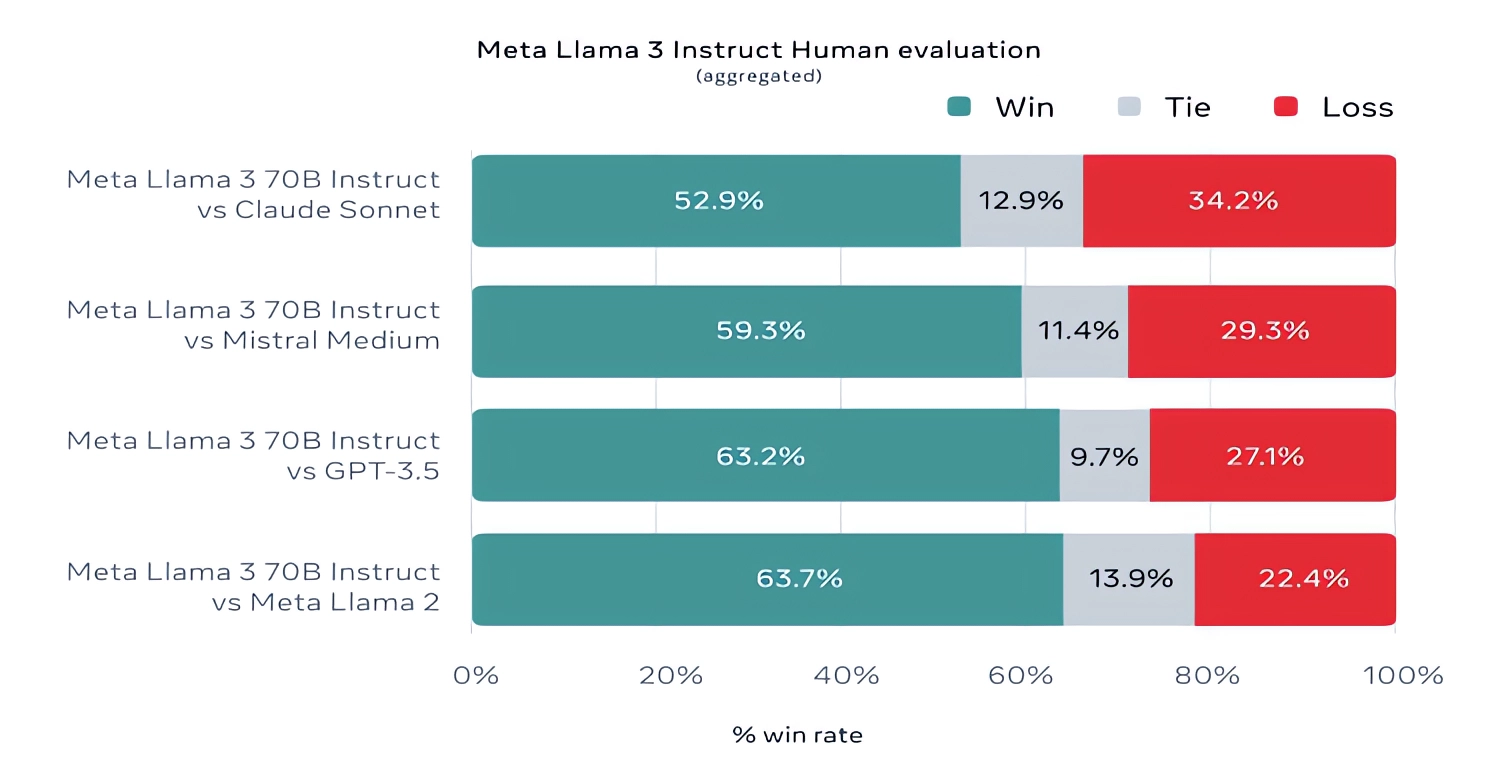
Para constar, a Meta também desenvolveu seu próprio conjunto de testes cobrindo casos de uso que vão desde codificação e escrita criativa até raciocínio e resumo e – surpresa! – Llama 3 70B saiu na frente contra o modelo Mistral Medium da Mistral, o GPT-3.5 da OpenAI e Claude Sonnet. A Meta diz que impediu que suas equipes de modelagem acessassem o conjunto para manter a objetividade, mas obviamente – dado que a própria Meta planejou o teste – os resultados devem ser vistos com cautela.
Créditos da imagem: meta
Mais qualitativamente, Meta diz que os usuários dos novos modelos Llama devem esperar mais “dirigibilidade”, uma menor probabilidade de se recusar a responder perguntas e maior precisão em perguntas triviais, questões relativas à história e campos STEM, como engenharia e ciência e codificação geral. recomendações. Isso se deve em parte a um conjunto de dados muito maior: uma coleção de 15 trilhões de tokens, ou cerca de 750 milhões de palavras – sete vezes o tamanho do conjunto de treinamento do Llama 2. (No campo da IA, “tokens” referem-se a bits subdivididos de dados brutos, como as sílabas “fan”, “tas” e “tic” na palavra “fantástico”.)
De onde vieram esses dados? Boa pergunta. Meta não quis dizer, revelando apenas que se baseou em “fontes publicamente disponíveis”, incluiu quatro vezes mais código do que no conjunto de dados de treinamento do Llama 2 e que 5% desse conjunto possui dados em outros idiomas (em cerca de 30 idiomas) para melhorar desempenho em outros idiomas além do inglês. A Meta também disse que usou dados sintéticos – ou seja, dados gerados por IA – para criar documentos mais longos para os modelos do Llama 3 treinarem, uma abordagem um tanto controversa devido às possíveis desvantagens de desempenho.
“Embora os modelos que estamos lançando hoje sejam ajustados apenas para resultados em inglês, a maior diversidade de dados ajuda os modelos a reconhecer melhor nuances e padrões e a ter um desempenho forte em uma variedade de tarefas”, escreve Meta em uma postagem de blog compartilhada com o TechCrunch.
Muitos fornecedores de IA generativa veem os dados de treinamento como uma vantagem competitiva e, portanto, mantêm-nos e as informações referentes a eles sob controle. Mas os detalhes dos dados de treinamento também são uma fonte potencial de ações judiciais relacionadas à PI, outro desincentivo para revelar muita coisa. Relatórios recentes revelou que a Meta, em sua busca para acompanhar os rivais da IA, a certa altura usou e-books protegidos por direitos autorais para treinamento em IA, apesar das advertências dos próprios advogados da empresa; Meta e OpenAI são objeto de um processo em andamento movido por autores, incluindo a comediante Sarah Silverman, sobre o suposto uso não autorizado de dados protegidos por direitos autorais para treinamento pelos fornecedores.
E quanto à toxicidade e ao preconceito, dois outros problemas comuns com modelos de IA generativos (incluindo Lhama 2)? O Llama 3 melhora nessas áreas? Sim, afirma Meta.
Meta diz que desenvolveu novos pipelines de filtragem de dados para aumentar a qualidade dos dados de treinamento de seu modelo e que atualizou seu par de suítes generativas de segurança de IA, Llama Guard e CybersecEval, para tentar evitar o uso indevido e gerações de texto indesejadas de Modelos Llama 3 e outros. A empresa também está lançando uma nova ferramenta, Code Shield, projetada para detectar códigos de modelos generativos de IA que possam introduzir vulnerabilidades de segurança.
A filtragem não é infalível, e ferramentas como Llama Guard, CyberSecEval e Code Shield só vão até certo ponto. (Veja: tendência do Llama 2 de inventar respostas a perguntas e vazar informações privadas de saúde e financeiras.) Teremos que esperar e ver o desempenho dos modelos Llama 3 em estado selvagem, incluindo testes de acadêmicos em benchmarks alternativos.
Meta diz que os modelos Llama 3 – que estão disponíveis para download agora e alimentam o assistente Meta AI da Meta no Facebook, Instagram, WhatsApp, Messenger e na web – em breve serão hospedados de forma gerenciada em uma ampla gama de plataformas de nuvem, incluindo AWS, Databricks, Google Cloud, Hugging Face, Kaggle, WatsonX da IBM, Microsoft Azure, NIM da Nvidia e Snowflake. Futuramente também serão disponibilizadas versões dos modelos otimizados para hardware da AMD, AWS, Dell, Intel, Nvidia e Qualcomm.
Os modelos Llama 3 podem estar amplamente disponíveis. Mas você notará que estamos usando “aberto” para descrevê-los em oposição a “código aberto”. Isso porque, apesar Reivindicações de Meta, sua família de modelos Llama não é tão sem compromisso como as pessoas imaginam. Sim, eles estão disponíveis para pesquisas e aplicações comerciais. No entanto, Meta proíbe os desenvolvedores usam modelos Llama para treinar outros modelos generativos, enquanto os desenvolvedores de aplicativos com mais de 700 milhões de usuários mensais devem solicitar uma licença especial da Meta que a empresa concederá – ou não – com base em seu critério.
Modelos Llama mais capazes estão no horizonte.
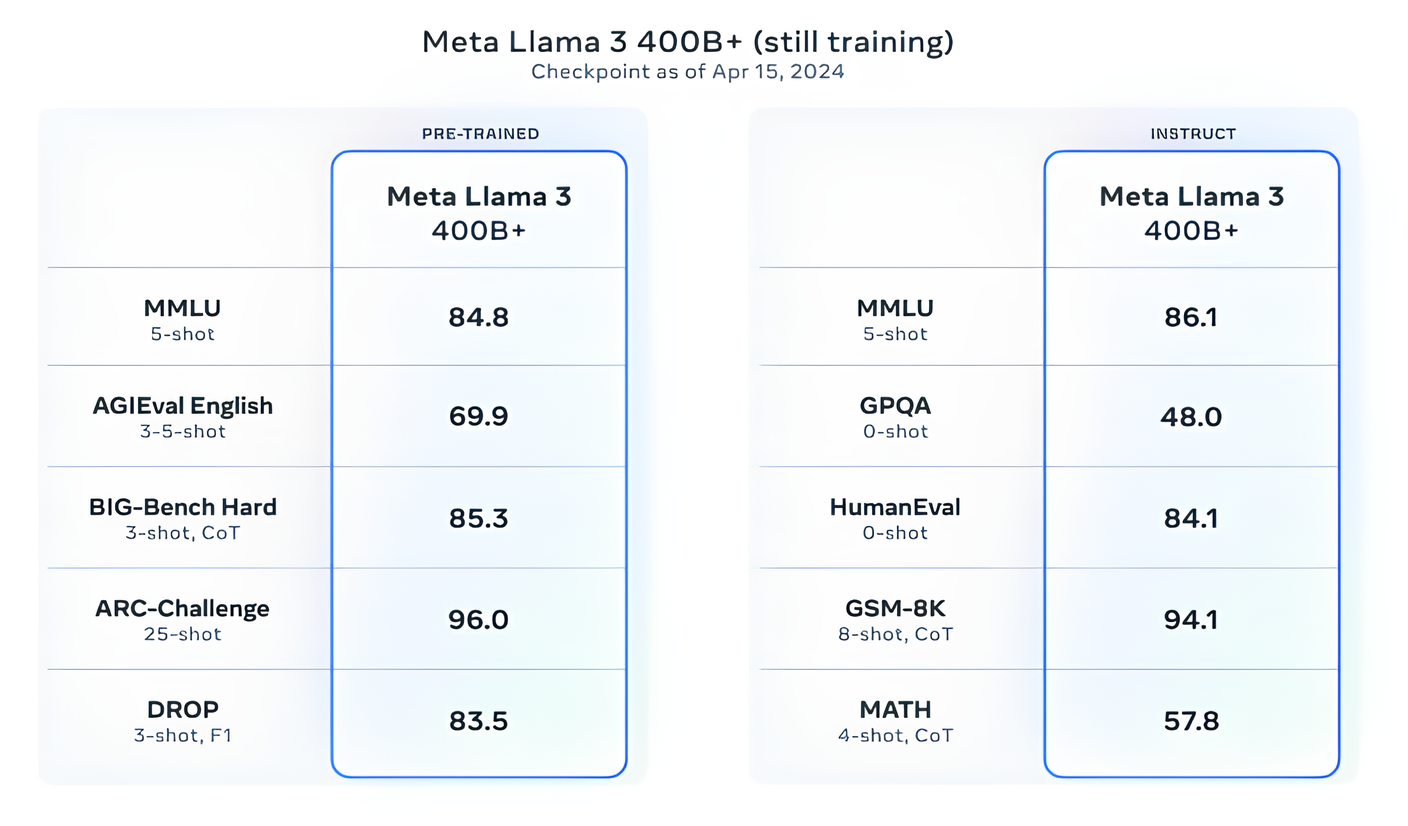
Meta diz que está atualmente treinando modelos Llama 3 com mais de 400 bilhões de parâmetros de tamanho – modelos com a capacidade de “conversar em vários idiomas”, absorver mais dados e compreender imagens e outras modalidades, bem como texto, o que traria a série Llama 3 em linha com lançamentos abertos como Hugging Face’s Idefics2.
Créditos da imagem: meta
“Nosso objetivo no futuro próximo é tornar o Llama 3 multilíngue e multimodal, ter um contexto mais longo e continuar a melhorar o desempenho geral em todos os principais setores. [large language model] capacidades como raciocínio e codificação”, escreve Meta em uma postagem no blog. “Há muito mais por vir.”
De fato.


{kind=link}